Perhaps you’re concerned about chatting with one of these publicly hosted LLMs, or you’ve continuously hit your limit on the number of questions asked. These are just a few of the reasons you may want to run an LLM locally.
I’ll be using docker to run these applications because I like being able to easily update them and not have to worry about the dependencies.
Below is the docker-compose file used to define the services that will be pulled and run:
services:
ollama:
ports:
- 11434:11434
volumes:
- ./ollama:/root/.ollama
container_name: ollama
pull_policy: always
tty: true
restart: unless-stopped
image: ollama/ollama:${OLLAMA_DOCKER_TAG-latest}
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
open-webui:
image: ghcr.io/open-webui/open-webui:${WEBUI_DOCKER_TAG-main}
container_name: open-webui
volumes:
- ./openwebui:/app/backend/data
depends_on:
- ollama
ports:
- ${OPEN_WEBUI_PORT-3001}:8080
environment:
- "OLLAMA_API_BASE_URL=http://ollama:11434/api"
- "WEBUI_SECRET_KEY="
restart: unless-stoppedI typically name this docker-compose.yml or something along those lines. A few things that need mentioning, wherever you save this file, you need to create the directories “ollama” and “openwebui”. These directories will be filled with data required to run the containers successfully.
Take note of the ports in use as well, 11434 for ollama and 3001 for open webui.
With the docker-compose file in place and the directories created, simply use the command:
docker compose upTo pull the containers and start the services. You can use the ‘-d’ option to have it run in the background, but I like to see the output on the first run to see if any errors occurred.
You should be able to see that the services are running correctly by navigating to: http://localhost:11434/ for ollama, and http://localhost:3001/ for open-webui. You can also check the state of the containers using:
docker psWhen navigating to open-webui, you’ll be greeted by a login screen. Create an account and login to see a home screen like this:
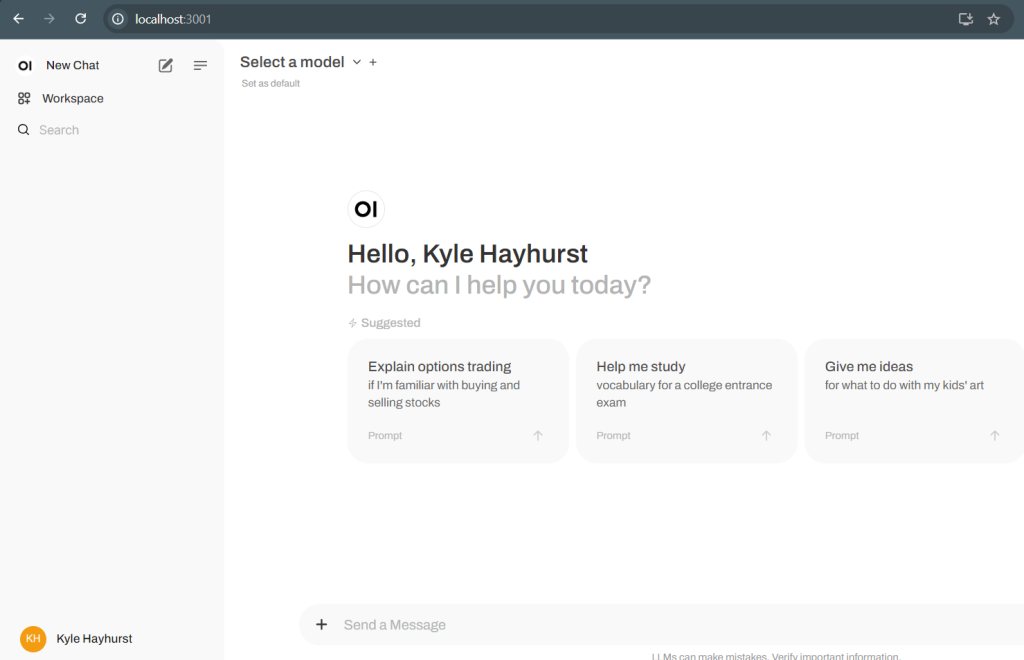
You’ll notice that there are no models loaded, ollama does not install a default model for you to interact with. On the ollama github, you’ll see a bunch of CLI references. But if you’re not that familiar with docker, you may ask, how do you run these CLI commands if we’re just running docker containers. There are some options, specifically ‘-it’, that allow us to connect to a container and open a terminal session.
You’ll need the “docker ps” command to display the container’s ID.

Then use it with the docker exec -it {CONTAINER ID} bash command. Replace the container ID with the one associated to you ollama container, and don’t use curly braces, like so:
docker exec -it 1ee1cabfe771 bashThis should get you into the container to run commands such as “ollama list” which shows you the list of downloaded models, which is likely still empty.

Running the command “ollama pull llama3.1” will download the LLaMa 3.1 model. Once it’s complete you can see the model has downloaded by running the “ollama list” command.
Simply refresh the open-webui page and you should now be able to select this model from the dropdown.
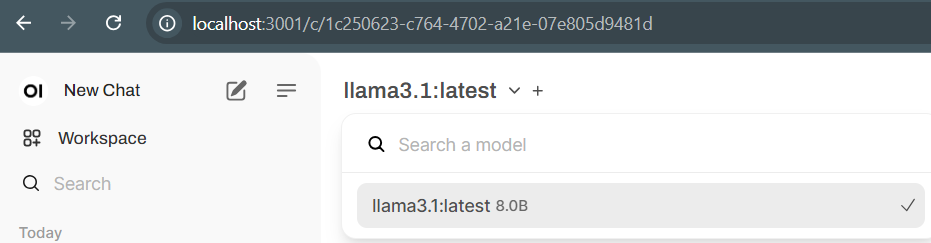
This is all you need to start chatting with LLaMa 3.1. This will likely be a base for other projects I work on using AI so I’ll leave this post short and simple.
If you happen to see where I could improve anything, feel free to leave a comment!
Leave a Reply